

The Pydantic Membrane
Why Pydantic is the foundation for LLM Agents

The first time I wired an LLM to a function I'd written, I needed three separate things, and I built all three by hand.
I needed a JSON schema to tell the model what arguments my function took. I needed a parser to turn the model's reply into something Python could use. And I needed validation, because the model would cheerfully hand me a field that didn't exist, or a string where I wanted an integer, and I had to catch that before it reached my actual code. Three layers. About twenty lines each. Each one had bugs the other two didn't catch, and the worst bugs lived in the seams between them — the schema said one thing, the parser assumed another, the validator checked a third.
But soon I realized that a single Pydantic BaseModel does all three jobs, and the class definition is five lines. I went back to my agent and deleted about eighty lines of parsing code. This post is about why that works, because it looks obvious in retrospect and it was not obvious the first time.
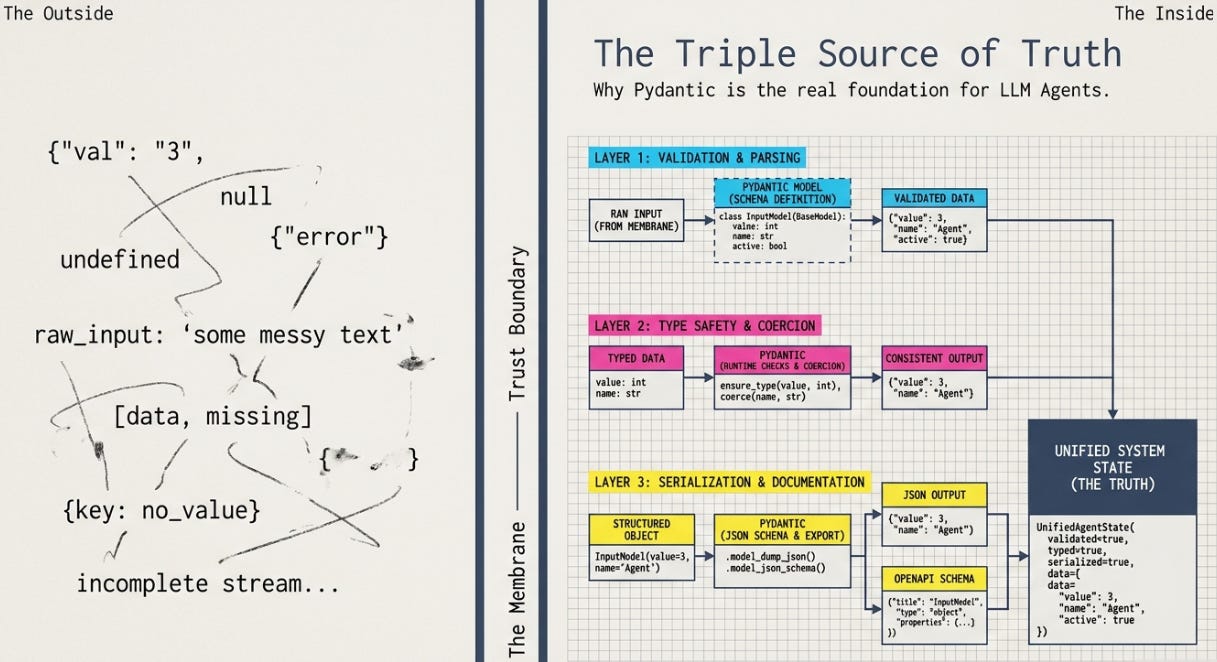
The three-layer problem
Here’s the shape of what I was doing. A write_file tool, hand-wired end to end:
# Layer 1: the schema I hand-wrote so the LLM knows the tool's arguments
WRITE_FILE_SCHEMA = {
"name": "write_file",
"description": "Write text to a file",
"input_schema": {
"type": "object",
"properties": {
"path": {"type": "string"},
"content": {"type": "string"},
"mode": {"type": "string"}, # "overwrite" or "append" -- enforced where, exactly?
},
"required": ["path", "content"],
},
}
# Layer 2 + 3: parse the LLM's reply, then validate it by hand
def handle_write_file(raw_args: dict):
if "path" not in raw_args:
raise ValueError("missing path")
if "content" not in raw_args:
raise ValueError("missing content")
mode = raw_args.get("mode", "overwrite")
if mode not in ("overwrite", "append"):
raise ValueError(f"bad mode: {mode}")
path = str(raw_args["path"])
# ...and on, and on, for every field of every tool
return write_file(path, raw_args["content"], mode)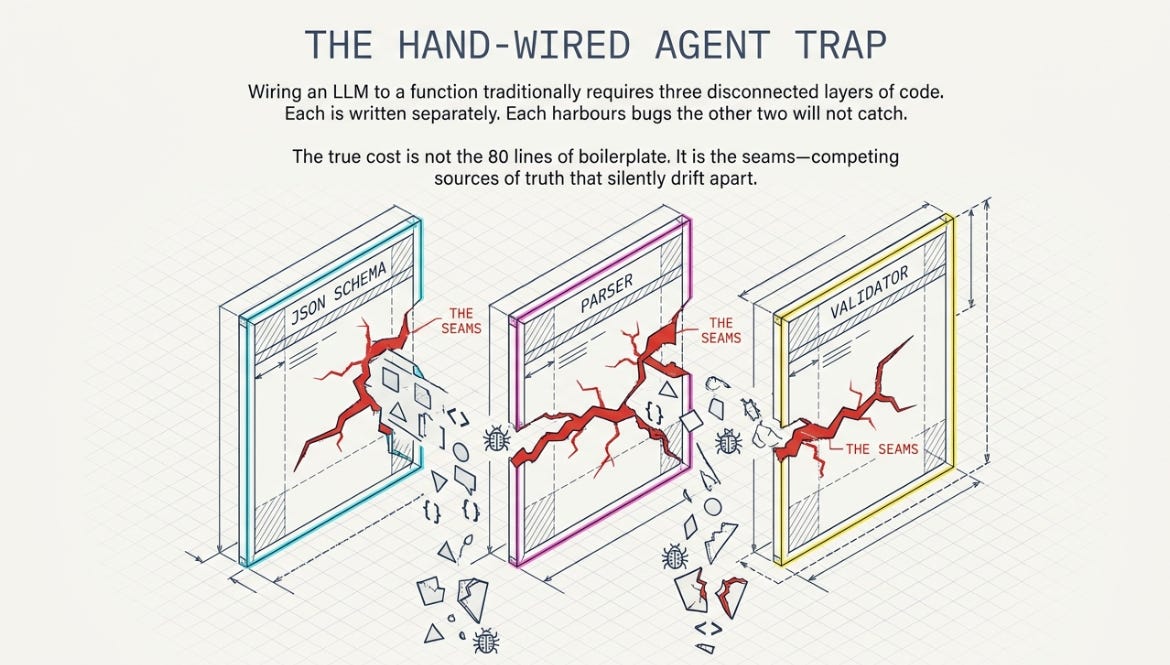
The boilerplate isn’t even the real cost. The real cost is that the three layers are three separate sources of truth that have to agree, and nothing forces them to. Add a mode field to the schema and forget to add it to the validator, and the model can pass garbage straight through. Multiply by every tool in your agent. That’s the eighty lines I deleted, and most of them were the seams.
One class, three uses
Here is the same tool as a Pydantic model:
from pydantic import BaseModel, Field
from typing import Literal
class WriteFile(BaseModel):
path: str = Field(description="Filesystem path to write to")
content: str = Field(description="The text to write")
mode: Literal["overwrite", "append"] = "overwrite"
That one class does all three jobs, and each is one method call.
# USE 1 — generate the tool definition you send to the LLM
tool = {
"name": "write_file",
"description": "Write text to a file",
"input_schema": WriteFile.model_json_schema(),
}
# USE 2 — turn the LLM's raw reply into a validated object (parse + validate, together)
args = WriteFile.model_validate(raw_args) # raises if path missing, mode invalid, etc.
# USE 3 — use it as an ordinary, typed Python object
write_file(args.path, args.content, args.mode)
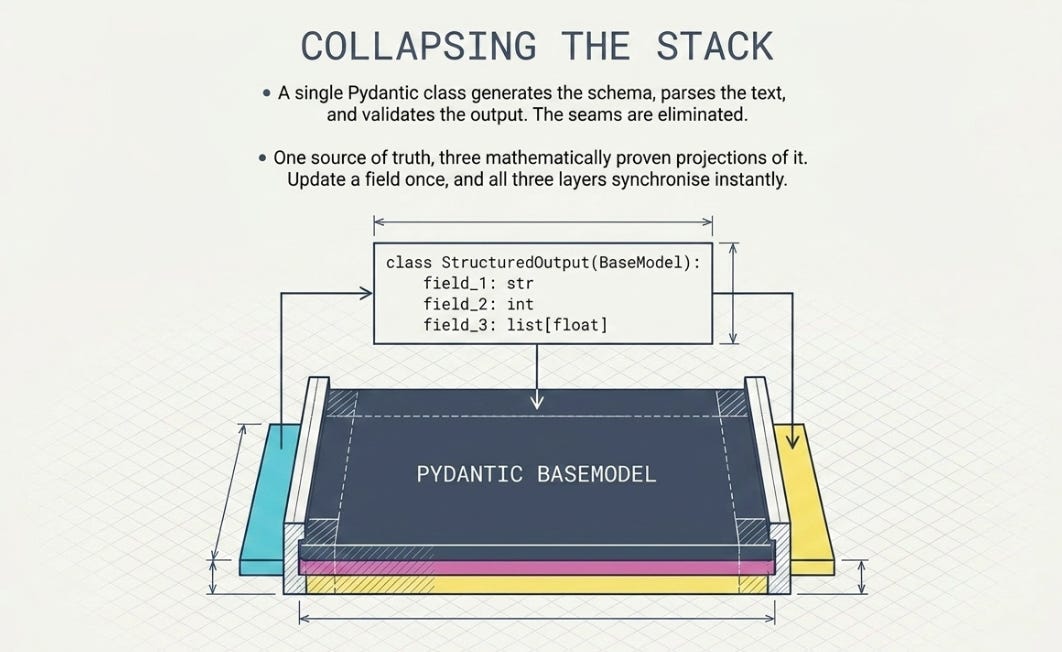
The schema, the parser, and the validator are now the same five lines, and they cannot drift apart, because they’re generated from one definition. Add a field and all three jobs update at once. The seams are gone because there’s nothing to seam.
The win isn’t fewer lines. It’s that the schema the LLM sees, the validation that guards your code, and the type your code uses are now provably the same thing. One source of truth, three projections of it.
Why coercion matters for LLMs specifically
There’s a detail here that’s easy to skip past and is actually the whole reason this fits LLMs so well. Models return text. Even when you ask for a number, what comes back over the wire is often a string — "3", not 3. A hand-rolled parser has to remember to cast every numeric field, every time, and you find the one you forgot in production.
Pydantic coerces by default. Hand it "3" for an int field and you get 3:
class Delay(BaseModel):
seconds: int
Delay.model_validate({"seconds": "3"}).seconds # -> 3 (the string was coerced)
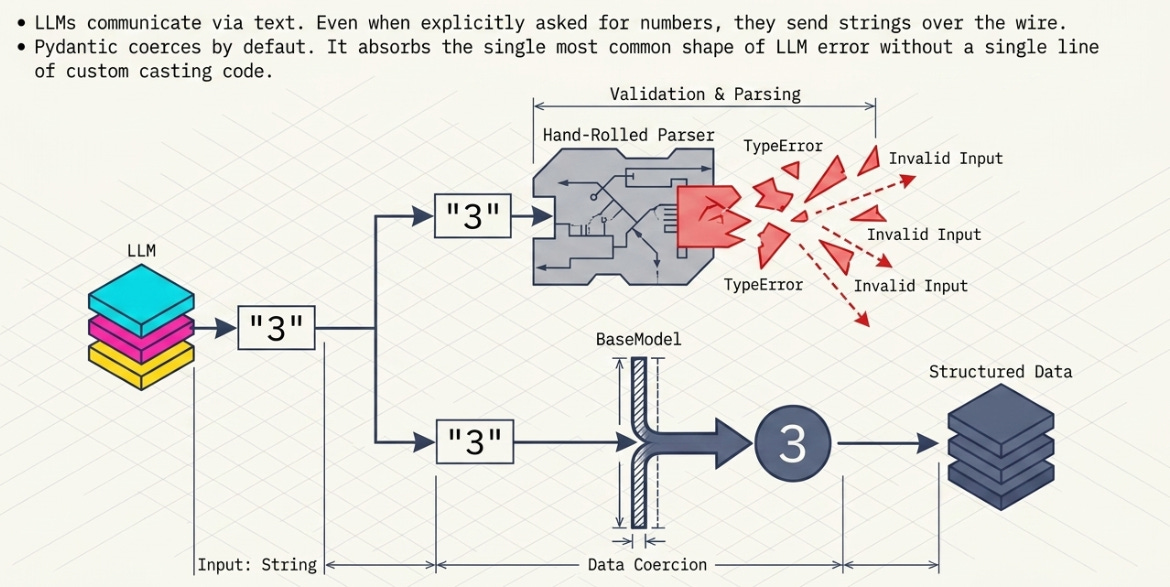
This is very helpful — it absorbs the single most common shape of LLM sloppiness without a line of code from you. But coercion is also the thing that will bite you if you’re not paying attention, so I want to be honest about it rather than sell it.
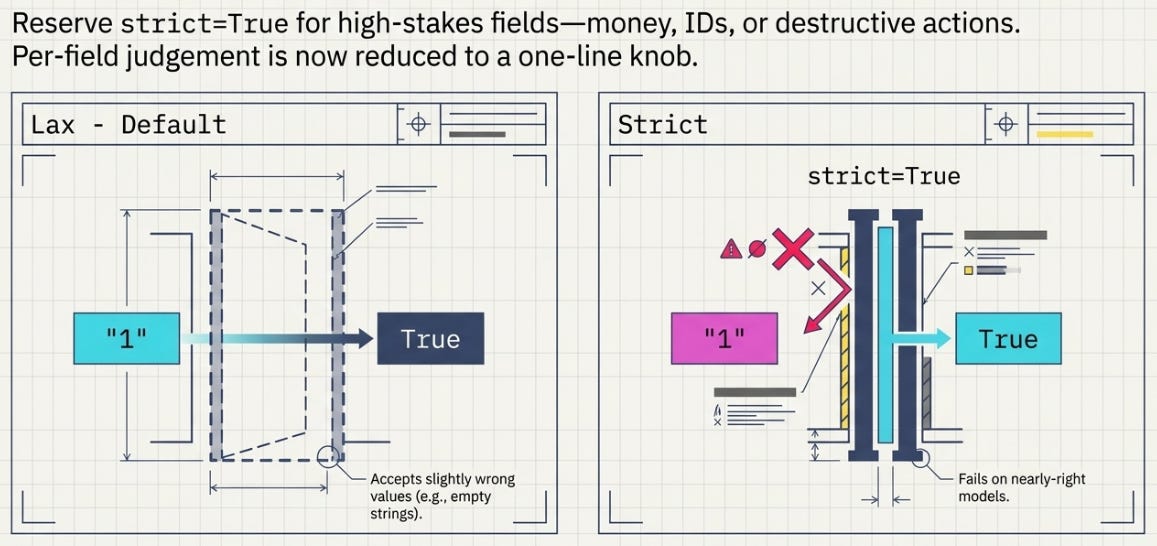
Lax coercion will accept things you might not want. "1" becomes True for a bool field; an empty string can slip through where you expected a real value. If a field is one where you’d rather the model be exactly right than be helpfully corrected, turn coercion off for that model:
from pydantic import ConfigDict
class Transfer(BaseModel):
model_config = ConfigDict(strict=True) # no silent string->int; the LLM must send the real type
amount: intThe trade-off is real and it goes both ways. Lax mode tolerates a forgetful model and risks accepting a wrong value; strict mode catches the wrong value and fails more often on a model that was nearly right. I use lax almost everywhere and reserve strict=True for the handful of fields where a quietly-coerced value would be dangerous — money, ids, anything destructive. There’s no universally correct setting; there’s a per-field judgment, and Pydantic at least makes it a one-line knob instead of a parser rewrite.
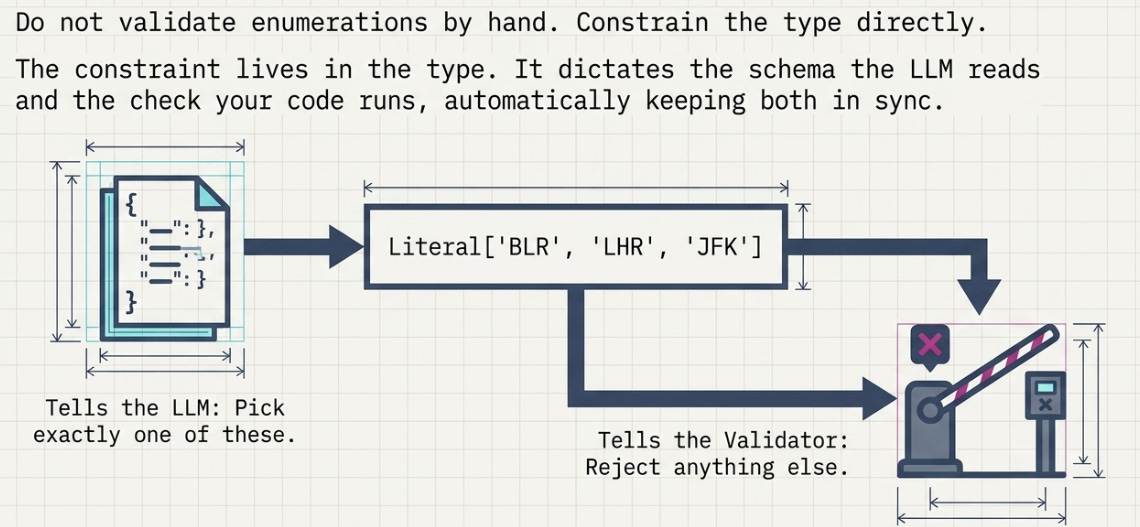
For fields that should only ever be one of a few values, don’t validate by hand — constrain the type:
mode: Literal["overwrite", "append"] = "overwrite"Literal does two jobs at once: it shows up in the generated schema as an enum, so the model is told the allowed values, and it rejects anything else at validation time. The constraint lives in the type, which means it’s in the schema the LLM reads and the check your code runs, automatically in sync.
The trust boundary rule
Once you’ve internalized “one class, three jobs,” a clean rule falls out of it, and it’s the one I’d actually tattoo on a junior engineer: use BaseModel at every boundary the LLM touches, and a plain @dataclass for data that never crosses that line.

The distinction between @dataclass and BaseModel in agentic engineering
The reasoning is about where untrusted data enters. Anything coming from the model is untrusted — it could be malformed, hallucinated, or just the wrong type — so it has to pass through a validating boundary, and BaseModel is that boundary.
Once data is inside, validated, and flowing between your own functions, re-validating it on every hop is wasted work; a @dataclass is lighter and says, structurally, “this is trusted internal state.” The model type marks the membrane. When I read my own code now, BaseModel tells me “the LLM was here,” and @dataclass tells me “this never left the building.” That’s documentation I get for free from the type choice.
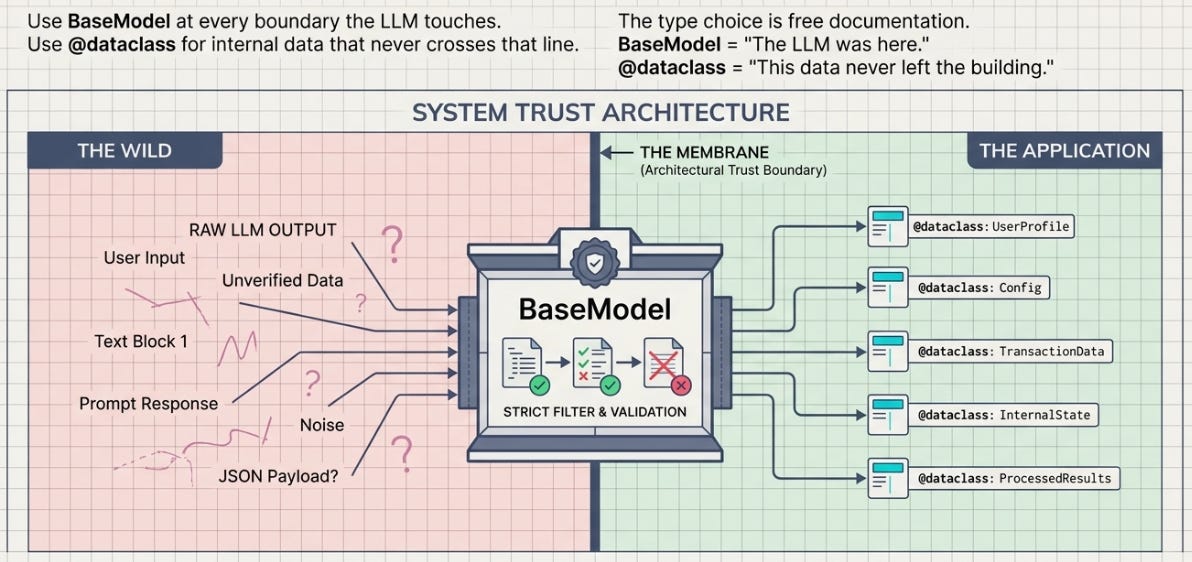
Pick the type by where the data came from.
BaseModelmeans “this crossed the LLM membrane and was checked.”@dataclassmeans “this is ours, already trusted.” The type is the trust boundary, written down.
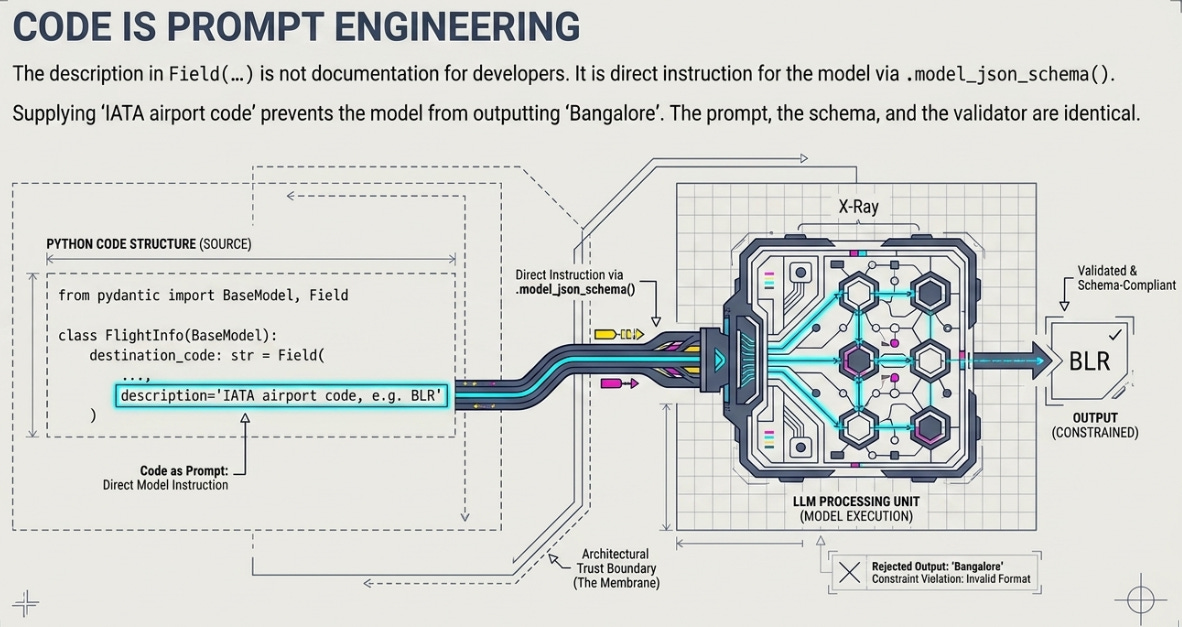
The Field description is prompt engineering
Here’s the part that surprised me most. The description you put in Field(...) is not documentation for you. It’s text the model reads when it’s deciding whether and how to call the tool, because model_json_schema() carries those descriptions straight into the schema you send the LLM.
class SearchFlights(BaseModel):
origin: str = Field(description="IATA airport code to depart from, e.g. 'BLR'")
destination: str = Field(description="IATA airport code to arrive at, e.g. 'JFK'")
date: str = Field(description="Departure date in ISO format YYYY-MM-DD")Those three strings are prompt engineering, and they live inside your class definition instead of in some separate system prompt. “IATA airport code, e.g. ‘BLR’” is the difference between the model passing BLR and the model passing Bangalore. You can fix more tool-calling bugs by editing a Field description than by editing the model or the surrounding prompt. The class is where your prompt for that tool actually lives — which means the prompt, the schema, and the validator are, once again, the same object.
Where a type annotation runs out: cross-field validators
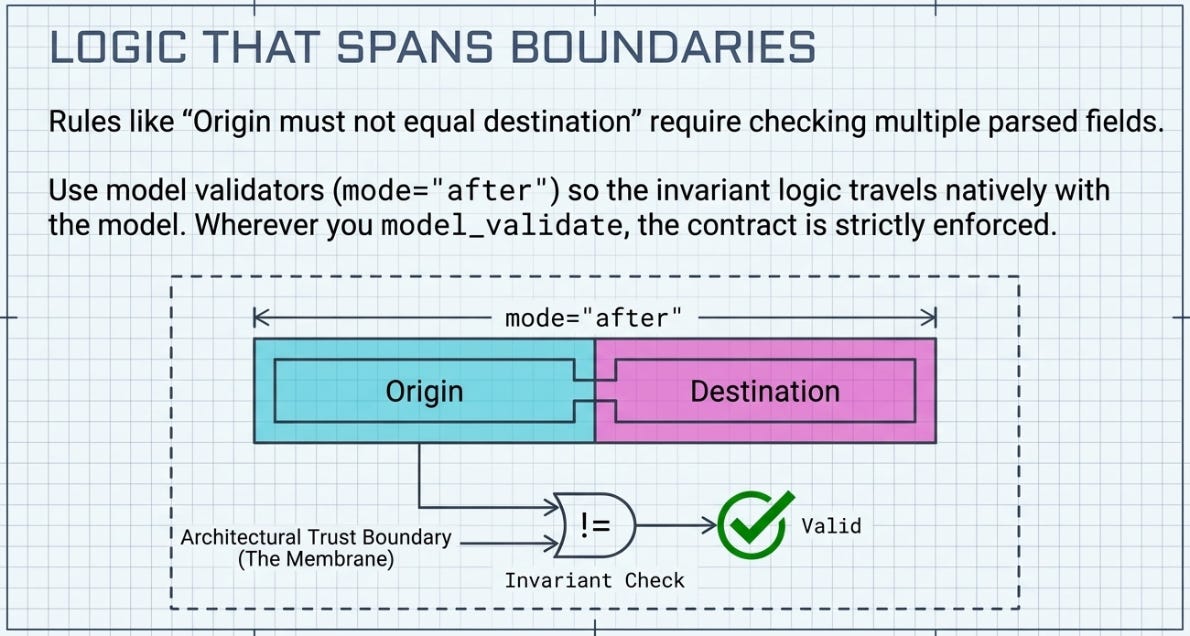
Some rules can’t be expressed as a single field’s type. “Origin must not equal destination” is about two fields together. That logic has to live somewhere, and the somewhere is a validator on the model — not scattered through your handler functions where it’ll drift out of sync with the schema again.
from pydantic import model_validator
class SearchFlights(BaseModel):
origin: str
destination: str
@model_validator(mode="after")
def origin_differs(self):
if self.origin == self.destination:
raise ValueError("origin and destination must differ")
return selfmode="after" runs once the individual fields are already parsed and typed, so you’re checking real values, not raw strings. The invariant now travels with the model: anywhere you model_validate a SearchFlights, the check runs. You can’t forget it, because it’s part of the contract.
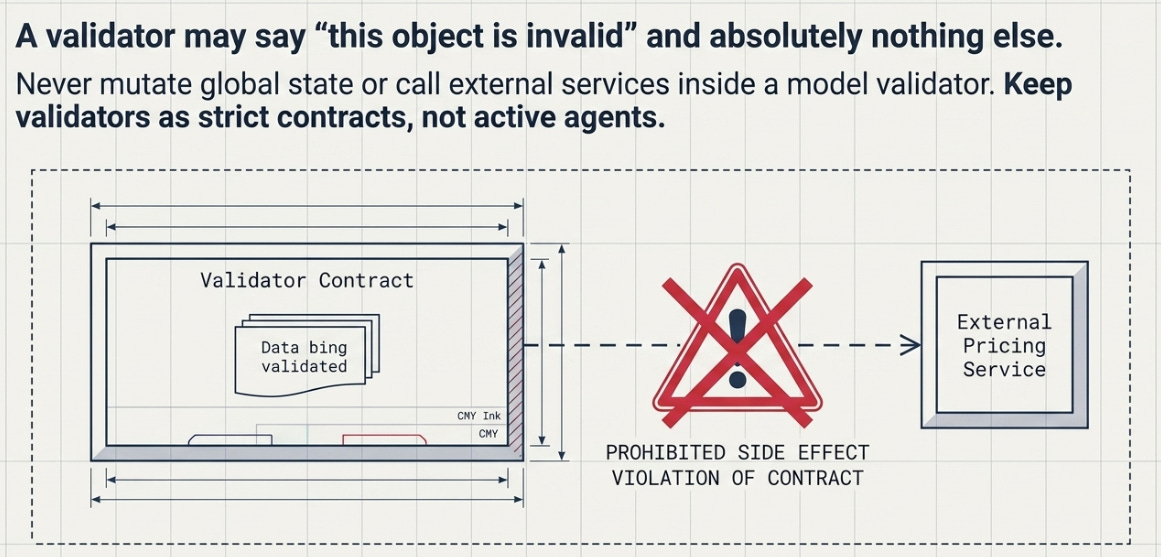
One caution I'd give from experience: keep validators to invariants, not side effects or business logic.
A validator that rejects origin == destination is a contract. A validator that calls your pricing service, or mutates global state, or does real work, is a landmine — it runs at construction time, in places you won't expect, and it makes a simple model_validate do things it shouldn't. The rule to follow: a validator may say "this object is invalid" and nothing else. The moment it wants to do something, that belongs in your handler, not your model.
What this doesn’t fix
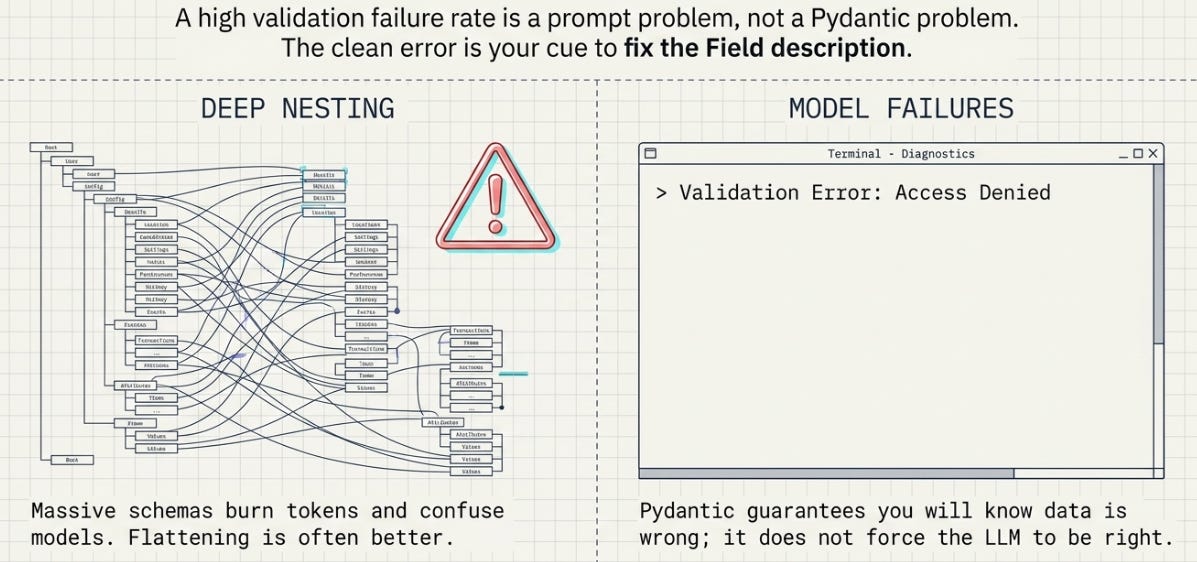
Pydantic removes the parsing-and-validation tax. It does not make the model send you correct data — it only guarantees you’ll know when the data is wrong, at the boundary, with a clear error, instead of three functions deep with a KeyError. That’s a big deal, but it’s a different promise than “the agent works.”
Two honest edges. Deeply nested models produce large schemas, and a sprawling schema is more tokens in every tool-calling request and, sometimes, a model that gets confused by the structure — there’s a point where flattening a model helps the LLM even though it’s “worse” data modeling. And validation failures are a signal you still have to handle: a model that fails model_validate half the time isn’t a Pydantic problem, it’s a prompt or a field-description problem, and the clean error is your cue to go fix the description, not to wrap the call in a bare except. The clean boundary is useful precisely because it tells you which side the bug is on.
Your model is the contract
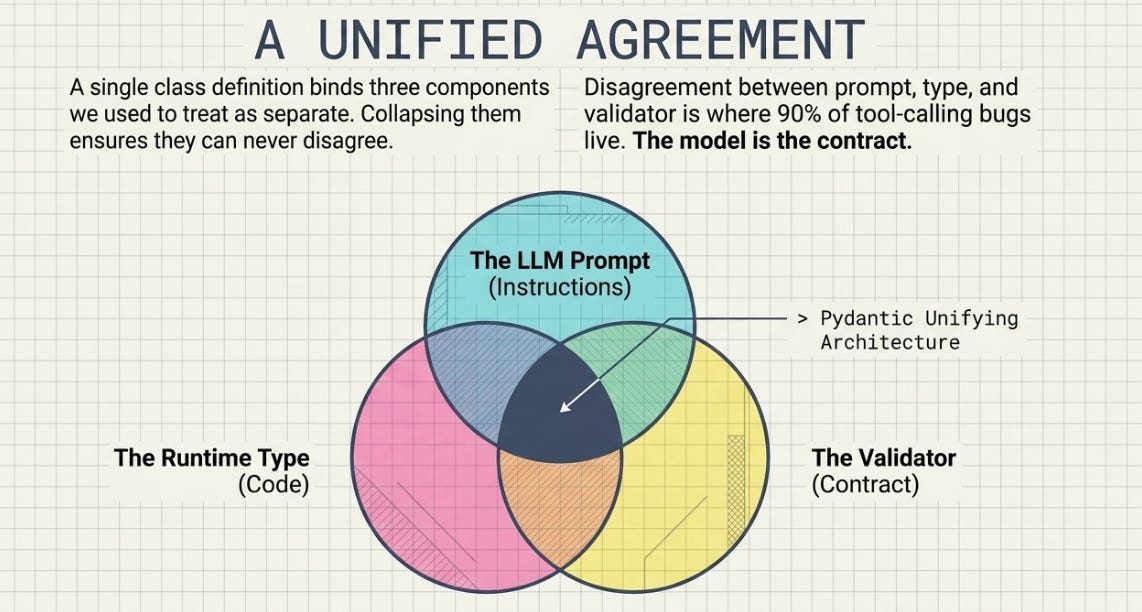
The thing I didn’t see the first time is that a class definition can hold three things at once that I’d been treating as separate: a prompt (the field descriptions the model reads), a validator (the types and the invariants), and a runtime type (the object my code uses). Collapsing them into one definition isn’t a tidiness win. It’s that they can no longer disagree with each other, and almost every tool-calling bug I’d been chasing lived in exactly that disagreement.
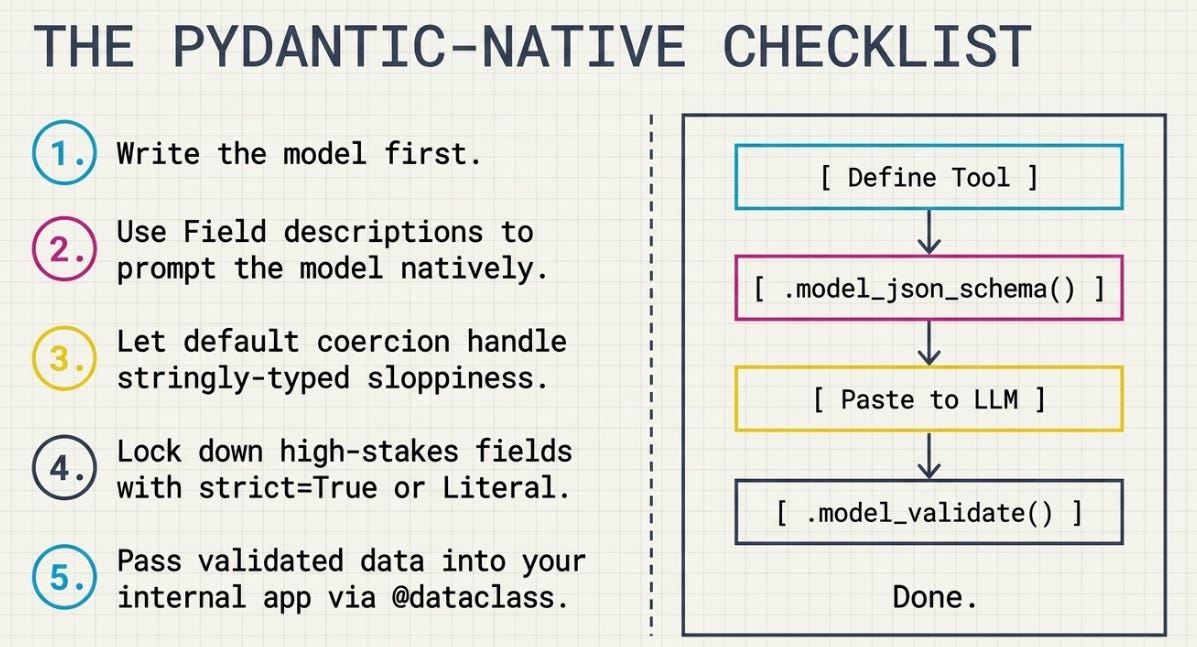
So the rule I’d give my past self, the one staring at three hand-written layers: write the model first. The model is your contract — with the LLM that has to produce it, with the code that has to consume it, and with the next person who reads it and learns, from the type alone, exactly what crosses the line and what doesn’t.
Subscribe and share if you liked this article!!