

Understanding (RoPE) Rotary Position Embeddings - 1
From Llama to DeepSeek, How Rotation Helps Models Remember Order!!

From Llama to DeepSeek, How Rotation Helps Models Remember Order
Transformers don’t inherently understand order — RoPE gives them a geometric memory of where each token belongs. In this guide, I break down how Rotary Position Embeddings work, why they outperform older positional methods, and how innovations like Decoupled RoPE push even further.
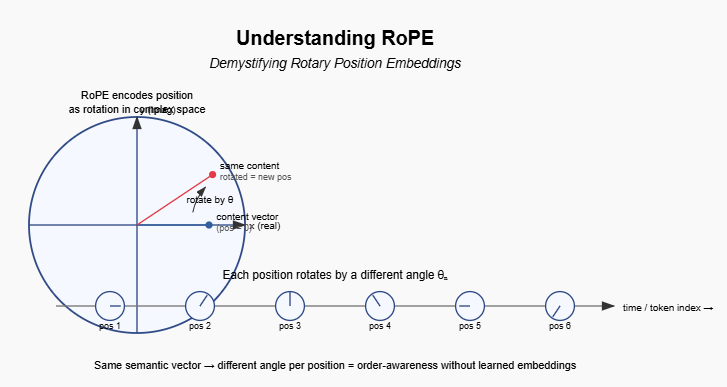
Why does information about word positions in a sequence matter?
Consider how transformers process text. When the model sees “The cat sat on the mat,” it converts each word into a vector — a point in high-dimensional space. But here’s the problem: these vectors contain no information about order. To the attention mechanism, “cat sat” and “sat cat” look identical. The model has no inherent notion of sequence.
This breaks language understanding. “Not good” means something different from “good not” (which isn’t even grammatical). “She told him the truth” has a different meaning when you swap “she” and “him.” Position matters.
Position embeddings solve this by injecting sequence information into each token’s representation. Early transformers used fixed sinusoidal patterns. GPT-2 learned separate embeddings for each position slot (position 0, position 1, position 2…).
Both work, but they expose limitations.
What should a good position encoding actually do?
Relative distances, not just absolute positions: The relationship between “not” and “good” matters whether they appear at positions (5, 7) or (105, 107). Absolute position slots waste capacity learning “position 47” when what matters is “2 tokens apart.”
Capture multiple distance scales simultaneously: Adjacent words form phrases (2–3 tokens). Sentences span dozens of tokens. Paragraphs extend hundreds. You need both short-range and long-range awareness in one mechanism.
Generalize beyond training lengths: Train on 2048 tokens, deploy on 8192. Learned embeddings have no representation for position 3000. The encoding must be algorithmic — a formula that extends infinitely, not a lookup table with fixed slots.
Rotary Position Embedding (RoPE) satisfies all three requirements through an elegant idea: encode position by rotating embedding vectors in high-dimensional space.
Encode position by rotating embedding vectors in high-dimensional space
Why encode position through rotation?
The alternative is simpler: just add a position vector to each token embedding. This is what sinusoidal embeddings do — add sin(pos) and cos(pos) patterns to your token vectors. It works, but addition blends position and content together. Once added, you can’t cleanly separate “what the token means” from “where it appears.”
Rotation preserves the original information while transforming it based on position. The magnitude stays the same, only the direction changes. More importantly: rotation creates a natural notion of relative position through angles.
If position is angle; distance is rotation.
But here’s the constraint: you can’t rotate a single number.
1D Limitation:
Think about what rotation means mathematically. A number on a line — say, 5 — can only be scaled (multiply by 2 → 10) or negated (multiply by -1 → -5). There’s no operation that “rotates” it while preserving its magnitude. Rotation requires at least two dimensions — a plane where you can move around a circle.
What cannot spin alone must pair
This is why RoPE works with pairs of dimensions.
From 1D to 2D:
Take a simple 4-dimensional embedding: [5, 3, 2, 7]
RoPE splits this into two pairs:
Pair 0:
(5, 3)← treat as a point on a 2D planePair 1:
(2, 7)← another point on a different 2D plane
Now rotation makes sense. The point (5, 3) can rotate around the origin. At position 0, it stays at (5, 3). At position 5, it might rotate to (4.2, 4.1). At position 10, it rotates further to (2.1, 5.5).
The key mechanism:
The same token embedding [5, 3, 2, 7] becomes different after rotation depending on position:
Token “cat” at position 0:
[5, 3, 2, 7](no rotation)Token “cat” at position 5:
[4.2, 4.1, 1.8, 7.2](rotated)Token “cat” at position 10:
[2.1, 5.5, 0.5, 7.4](rotated more)
Position information is now “baked into” the embedding through rotation angles.
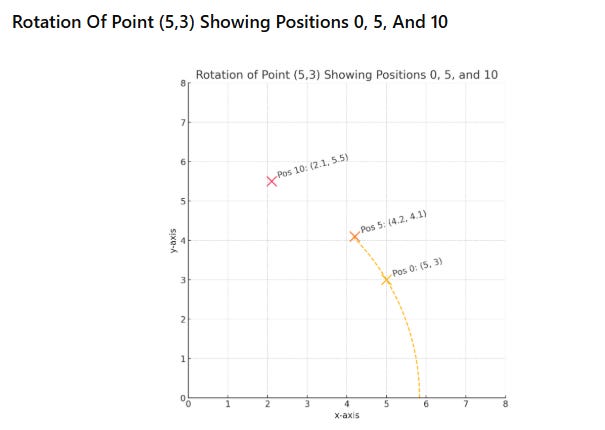
Position 0 → original point (5, 3)
Position 5 → rotated point (4.2, 4.1)
Position 10 → rotated further toward y-axis (2.1, 5.5)
The distance from origin stays constant (√34 ≈ 5.83)
The dashed arc shows the rotation path
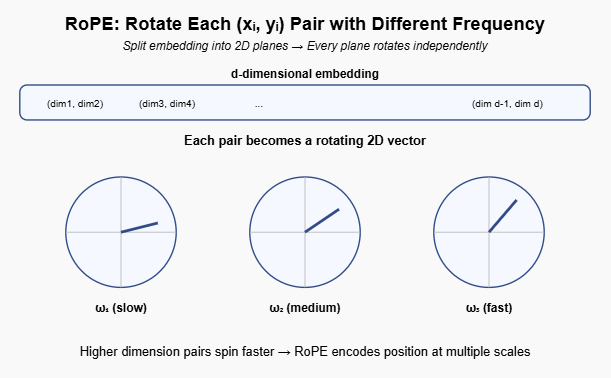
Each pair in embedding rotates independently in its own 2D plane. Your 64-dimensional head has 32 such planes, all rotating simultaneously at different speeds.
Each pair in embedding rotates independently in its own 2D plane
The Frequency Spectrum: Why Different Pairs Rotate at Different Speeds
Here’s where RoPE gets clever. If all 32 pairs rotated at the same speed, you’d have a problem: rotation is periodic. After 360°, you’re back where you started. Position 0 and position 1000 might look identical.
The solution: give each pair a different rotation frequency.
Fast and slow clocks:
Mental Model: Think of RoPE as having multiple clock hands rotating at different speeds. Fast hands (seconds) capture short-range patterns — words 2–3 tokens apart. Slow hands (hours) capture long-range patterns — relationships across hundreds of tokens. All hands rotate simultaneously, giving you multi-scale position awareness in one mechanism..
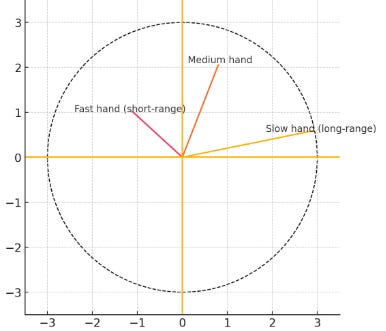
RoPE does the same thing across its 32 pairs:
Low-index pairs (0, 1, 2…): HIGH frequency → fast rotation → capture short-range patterns (2–5 tokens apart)
High-index pairs (30, 31): LOW frequency → slow rotation → capture long-range patterns (hundreds of tokens apart)
what spins fast sees near, what spins slow sees far.
The frequency for pair i is:
freq_i=1/(theta^(2i/head_dim))
Where theta = 100,000 (we’ll come back to why this specific number, refer to the last section for details).
What this means in practice:
Pair 0:
freq = 1 / (100000^0) = 1.0→ rotates fastestPair 15:
freq = 1 / (100000^(30/64)) ≈ 0.046→ medium speedPair 31:
freq = 1 / (100000^(62/64)) ≈ 0.00215→ rotates slowest
At position 100:
Pair 0 might have rotated through several full circles (capturing that position 100 is different from position 5)
Pair 31 has barely moved (capturing that positions 100 and 105 are relatively close in a long document)
The Origin of Theta = 10,000 (and variations)
The original RoFormer paper follows the Transformer’s sinusoidal embedding design, setting θᵢ = 10000^(-2i/d) — directly inheriting the value from Vaswani et al.’s “Attention Is All You Need.”
Why 10,000 originally?
The value comes from the original Transformer’s sinusoidal position embeddings, where the frequencies form a geometric progression from 2π to 10000·2π on the wavelengths. This range was empirically chosen to provide:
Fast frequencies for short-range dependencies
Slow frequencies for long-range context
Coverage up to reasonable sequence lengths (~2048 tokens)
different models use different theta values:
LLaMA 1 & 2 use base 10,000 (trained on 2K-4K tokens), while CodeLLaMA uses base 1,000,000 (trained on 16K tokens). For CodeLLaMA models, empirical perplexity tests show the best base frequency revolves around 100,000 for contexts up to 12,288 tokens.
The intuition:
Larger theta (100K, 1M) → slower rotation → better for longer sequences
Smaller theta (10K) → faster rotation → sufficient for shorter sequences
Lower values (500–1,000) provide high-frequency encoding for fine-grained dependencies, while higher values (20,000–50,000) offer lower frequencies for longer-range context.
Key takeaway: Theta isn’t derived from theory — it’s empirically tuned based on expected sequence length and task requirements.
Position determines the rotation angle:
The frequency tells you the speed of rotation, but position determines how far you’ve rotated:
angle = position × frequency
For pair i at position pos:
angle_i = pos × freq_i
angle_i = pos × (1 / theta^(2i/head_dim))Concrete example with pair 0 (highest frequency):
Position 0:
angle = 0 × 1.0 = 0°→ no rotationPosition 5:
angle = 5 × 1.0 = 5 radians ≈ 286°→ significant rotationPosition 100:
angle = 100 × 1.0 = 100 radians→ many full rotations
Same positions, but pair 31 (lowest frequency, freq ≈ 0.00215):
Position 0:
angle = 0 × 0.00215 = 0°→ no rotationPosition 5:
angle = 5 × 0.00215 ≈ 0.01 radians ≈ 0.6°→ barely movedPosition 100:
angle = 100 × 0.00215 ≈ 0.215 radians ≈ 12°→ still small rotation
This is the multi-scale magic: at position 100, pair 0 has wrapped around many times (distinguishing nearby positions), while pair 31 has barely rotated (treating distant positions as similar).
The complete rotation formula:
For a pair (x, y) at position pos with frequency freq:
x_new = x × cos(pos × freq) - y × sin(pos × freq)
y_new = x × sin(pos × freq) + y × cos(pos × freq)This is the 2D rotation matrix applied to each pair independently.
This preserves the distance from origin while changing the angle. For RoPE, we apply this to each pair of dimensions in our embedding.
Building the implementation step-by-step:
Let’s walk through the key operations. Starting with the angle calculation:
# Position indices: [0, 1, 2, ..., seq_len-1]
pos = torch.arange(seq_len)
# Frequency for each pair
i = torch.arange(0, head_dim, 2) # [0, 2, 4, ..., 62]
freqs = 1.0 / (theta ** (i / head_dim))
# Angle = position × frequency (outer product gives all combinations)
angles = torch.outer(pos, freqs) # shape: [seq_len, head_dim//2]the rotation angle for every position and every pair simultaneously.This outer product is crucial—it gives you the rotation angle for every position and every pair simultaneously.
angle is a function of both position in sequence and the pair of embedding dimension chosen
Applying the rotation:
# Precompute sin and cos
cos = torch.cos(angles) # shape: [seq_len, 32]
sin = torch.sin(angles) # shape: [seq_len, 32]
# Split embedding into even/odd dimensions (the pairs)
x_even = x[..., 0::2] # dimensions [0, 2, 4, ...]
x_odd = x[..., 1::2] # dimensions [1, 3, 5, ...]
# Apply rotation formula
x_even_new = x_even * cos - x_odd * sin
x_odd_new = x_even * sin + x_odd * cosInterleaving the rotated pairs:
After rotation, we have x_even_new and x_odd_new as separate tensors. We need to interleave them back into the original dimension ordering: [dim0, dim1, dim2, dim3, ...] instead of [dim0, dim2, ...] [dim1, dim3, ...].
The elegant solution uses stack and flatten:
# Stack creates a new dimension pairing even/odd together
x_rotated = torch.stack([x_even_new, x_odd_new], dim=-1)
# Shape: [..., 32, 2] where each pair is [even, odd]
# Flatten merges the last two dimensions, interleaving naturally
x_rotated = x_rotated.flatten(-2, -1)
# Shape: [..., 64] with dimensions back in orderComplete implementation:
class RotaryEmbedding(nn.Module):
def __init__(self, head_dim=64, rope_theta=100000):
super().__init__()
self.head_dim = head_dim
self.rope_theta = rope_theta
def forward(self, x):
# x shape: [batch, num_heads, seq_len, head_dim]
# Compute frequencies
i = torch.arange(0, self.head_dim, 2)
freqs = 1.0 / (self.rope_theta ** (i / self.head_dim))
# Compute angles for all positions
pos = torch.arange(x.shape[2])
angles = torch.outer(pos, freqs)
# Precompute sin/cos
cos = torch.cos(angles)
sin = torch.sin(angles)
# Split into pairs
x_even = x[..., 0::2]
x_odd = x[..., 1::2]
# Apply rotation (broadcasting cos/sin across batch and heads)
cos = cos.unsqueeze(0).unsqueeze(0)
sin = sin.unsqueeze(0).unsqueeze(0)
x_even_new = x_even * cos - x_odd * sin
x_odd_new = x_even * sin + x_odd * cos
# Interleave back
x_rotated = torch.stack([x_even_new, x_odd_new], dim=-1)
x_rotated = x_rotated.flatten(-2, -1)
return x_rotatedBake position into direction, not magnitude — separation preserves what addition destroys.
Summary: What We’ve Learned About RoPE
Position embeddings solve a fundamental problem: transformers have no inherent notion of word order. Without positional information, “cat sat” and “sat cat” are indistinguishable.
A good position encoding must satisfy three requirements:
Relative distances matter — The relationship between tokens at positions (5, 7) should match (105, 107)
Multi-scale awareness — Capture both short-range syntax and long-range document structure simultaneously
Extrapolation — Generalize beyond training sequence lengths through algorithmic generation, not memorization
RoPE’s core mechanism encodes position through rotation in high-dimensional space. Since you can’t rotate a single number, embeddings are split into pairs — each pair forms a 2D point that can rotate around the origin. The same token at different positions gets different rotated embeddings, “baking in” positional information.
Different pairs rotate at different frequencies, like clock hands. Fast-rotating pairs (high frequency) capture short-range patterns. Slow-rotating pairs (low frequency) track long-range dependencies. This spectrum of frequencies enables multi-scale position encoding in a single mechanism.
In the next part of this series we will explore the following:
Where RoPE is applied in attention mechanism.
How production implementation of RoPE happens.
DeepSeek’s decoupled RoPE.
👉 Enjoyed reading? Please subscribe 🔔, like ❤️, and share with others!